
L1 Cache architecture
之所以會看這個主題,是因為網路黑貓(Champ Yen)大大分享 ARM 從 virtual cache 轉到 physical cache 的利弊。雖然曾經從書上看過兩者差異性,不過沒搭配硬體架構,總覺得沒有好好了解。因此這篇整理了 ARM Programmer’s Guide 的內容,並透過實際例子來探討 VIVT (virtual indexed vritual tagged)、VIPT(virtual indexed physical tagged)、PIPT(physical indexed physical tagged) 的差異性。
Virtually Addressed Caches (VIVT)
十多年前的 ARM Processor L1 cache 採用 VIVT cache 架構,在當時的 ARM architecture reference 5.5.1 節有提及主要的原因:
It allows cache line look-up to proceed in parallel with address translation.
由於 cache access 和 address translation 可以同時執行,因此當有 cache miss 發生時,就能夠縮短取得 physical memory address 的時間 (reduce miss penalty)。另外,在一般情況下 cache hit 發生次數較多,因此 cache hit access 不用經由 address translation,對於提升效能也有幫助。
但也因為 virtual address 的特性,導致 VIVT cache 會產生一些嚴重問題,其中包含:
Problems
1. homonyms
不同 process 中有同一個 virtual address ,並指向不同的 physical address。因為 virtual address 相同,因此會使用同一個 cache line,當切換到另一個 process 時,會導致誤判成 cache hit 而取得錯誤 data。
2. synonyms
不同 virtual address 指向同一個 physical address,例如 mmap 或是多個 process 共享同一個資料。因為是不同 virtual address,也意味著同一份 data 會分別緩存在不同的 cache line,可能導致其中一個 process 更新 cache data 後,另一個 process 的 cache data 沒有被更新,因而取得較舊的數據。
Possible solutions
Flush Cache
而針對 cache 資料不一致的問題,一個直接又暴力的解法就是 flush cache。當 context switch 或是 context swap 時候,直接清空 cache data,重新地從 main memory 中取得。以 ARMv5 為例,因為 L1 cache 分成 data cache 和 instruction cache,其 flush cache 流程是:
- 如果data cache 為 write-back ,則清空
- invalidating the data cache
- invalidating the instruction cache
- 清除 write buffer
另外,virtual cache access 也需要考量 page permission 問題,因此 cache unit 實際上會去向 TLB 詢問此 virtual address 的 permission。因此當 context switch 時,TLB 也同樣地要需要 invalidate。
上述可以得知 flush cache 所帶來的成本相當高,畢竟每次 context swap 或是 switch 時都需要 clean 和 reload data。在 The ARM Fast Context Switch Extension for Linux 提到,context switch 時 flush cache 所造成的時間成本可能多達 200 microseconds,對 real-time 需求較高的 application 來說是蠻嚴重的問題。
Fast Context Switch Extension
為了降低 flush cache 次數,2009 年 ARM 採用軟體實作搭配 ARMv5 架構,提出 Fast Context Switch Extension 解法。FCSE 主要是用來解決不同 process 使用相同 virtual address range 問題。
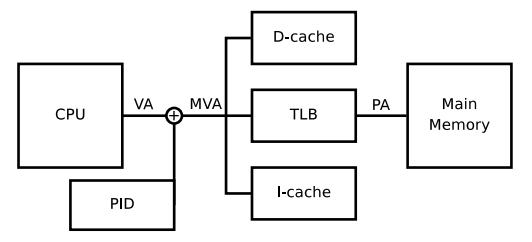
(圖片:The ARM Fast Context Switch Extension for Linux)
其概念是將 virtual address 的最高位前 7 bit 改成 process ID,如此一來不同 process 就能各自擁有不同的 virtual address range。不過這樣的設計問題就是 process 數量受到限制,7 bit 最多只能有 2^7 = 128 process 數量。論文中也有說明此機制適用在部份 embedded system 場景。
From Virtual Cache to Physical Cache
隨著應用場景複雜化和 multi-core processor 的發展,invalidating 和 clean cache 成本對效能逐漸造成不可忽視的影響(後續再補數據圖),從 ARM 在 Cortex-A series processors document 中有特別提及這點,因此從 ARMv6 開始,全部改採用 VIPT instruction cache / PIPT data cache L1 cache 架構。
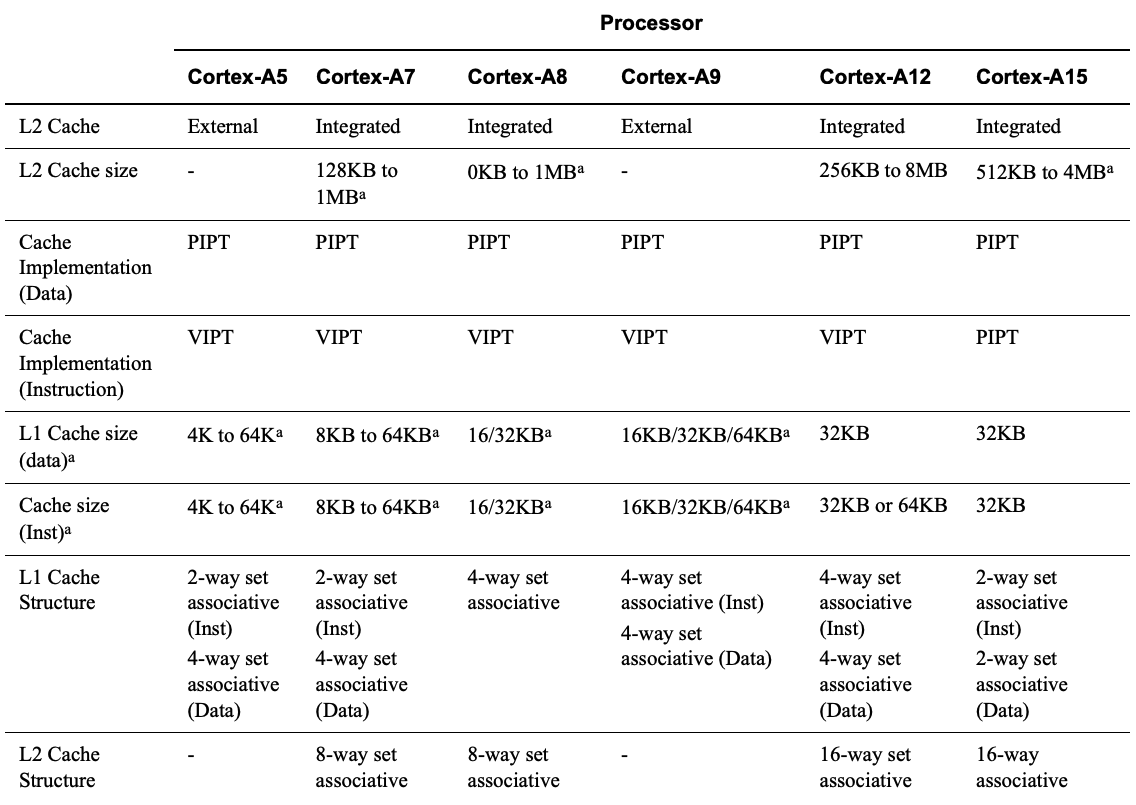
(圖片:ARM® Cortex™-A Series Programmer’s Guide)
Physically-addressed caches (VIPT)
ARM 現代處理器多數 L1 cache 已採用 physically-addressed cache,減少 VIVT 造成 cache coherency 問題。而之所以有 virtual indexed physical tagged (VIPT) cache,是為了在 address translation latency 和 cache access 中取得平衡。VIPT 機制中,index 取自 virtual address,因此可以先進行部分 cache line 查找流程,等 address tranlation 後取得 physical tag,再進行最後 tag 比對。
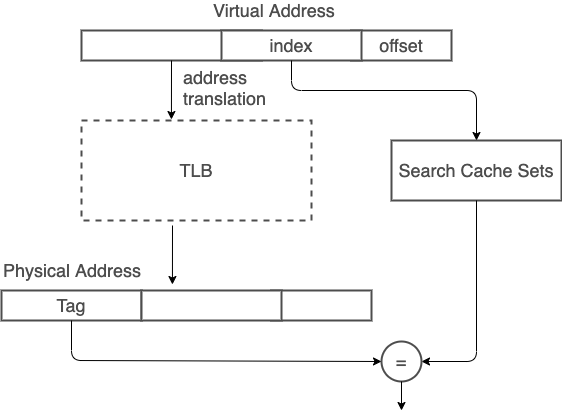
不過因為 VIPT 會使用到部分 virtual address,為了避免產生 VIVT 所造成的 synonyms 問題,在使用 VIPT 時會受限於 hardware 的 page size。
舉例來說,常見的 page size 是 4KB (2^12),所以 physical address 和 virtual address 的 0 - 11 bit 為相同數值。利用這特性,只要在這 12 bit 內分配 cache index 和 cache offset bit 數,就能夠確保一個 physical address data 只會在同一個 cache line 上。
如此一來,cache size 就會被限制在 2^12 * multi-way。像是 physical page size 為 4KB(2^12),cache line 為 64 (2^6) bytes,採用 four-way associative cache,則 cache size 大小就是 4KB * 4 = 16KB。

如果 page size 是 4KB,four-way associative cache size 是 64KB 會發生什麼事?
如果 cache size 是 64 KB,則 cache index 需要 8 bit,cache line 同樣為 6 bit, 8 + 6 = 14 多於 physical page size 的 12 bit,那麼多出來的 2 個 bit 就有可能因為 address translation 而發生 synonyms 問題。
Possible solutions - page coloring
面對上述產生的問題,其中一項解決方法就是 page coloring,就是將上述多出來的 2 bit 區分顏色, 2 bit 就會有 2^2 = 4 個顏色。並限制不同顏色需要對應到不同 physical page。如此一來就可以避免不同 virtual address 和不同 cache index 卻對應到同一個 physical address。
Physically-addressed caches (PIPT)
如果 cache size 不想受限於 page size,又要避免 page coloring,最簡單又直接的方式就是直接採用 PIPT 的方式,當然這也就增加 cache hit latency,不過相較於 context switch 所帶來的 VIVT 在 clean cache 成本和可能發生資料不一致性,PIPT 相對單純。在 ARMv6 之後的 L1 data cache 就是採用 PIPT。
VIPT v.s. PIPT
在上述提到的 ARM A 系列規格,可以發現到 L1 cache 中,instruction cache 是 VIPT four-way associative cache,而 data cache 是 PIPT four-way associative cache。是怎樣的考量才會讓這兩個 cache 在規格上有所差異?
在 ARM community 中就有人提過此問題:
Why is the I-cache designed as VIPT, while the D-cache as PIPT?
而 ARM 工程師給了解答:
PIPT caches are more flexible (can share data across processes without needing a cache flush on context switch), but more power intensive (I need to to a TLB lookup on every access rather than just on line-fill (i.e. when I miss)).
The instruction cache doesn’t generally need these advantages - it’s read-only - and the disadvantage is a significant one if you care about building a very power efficient core.
結尾
寫這篇文章同時,讓我想到在計算機結構課程,也有同學報告三星在 cache size 的變化,不過當時沒能仔細詢問三星之所以改變 cache size 的考量,這次藉由 ARM 架構研究,讓我在之後看硬體架構時,會更注意背後設計的原因。
References
- ARM926EJ-S Technical Reference Manual
- The ARM Fast Context Switch Extension for Linux
- ARM® Cortex™-A Series Programmer’s Guide
- ARM architecture reference manual