
接續前面文章提及到,在上傳檔案的使用情境之下,因為 user request 數量增多,造成 service lead time 大幅提升的問題;而導致 lead time 增加的因素,根據實驗數據,主要是因為:
- The different implementation methods of receiving the file
- The concurrency model of language runtime
若要從根本來改善此問題,需要從兩個層面來著手:
- Client side: user 如何傳送夾帶檔案內容的 request 到 server
- Server side: server 如何依據 client 發送 request 的流程來處理此檔案
透過使用者訪談後,我們預期的使用情境,包含:
- 檔案會使用
multipart/form-data的方式來傳送,另外 form-data 中也會包含額外 server 所需的資訊 - 其傳送的檔案大小不定,最大可以至 1G
- Client 會使用 HTTP/1.1 protocol 來發送 requests
在這樣的使用前提之下,我們就可以來研究 client 端是如何來發送 request,並進而從 server 端來進行改善。
The previous article mentioned that in the context of uploading files, an increase in user request volume leads to a significant increase in service lead time. According to experimental data, the main factors contributing to this increase in lead time are:
- The various implementation methods of receiving the file.
- The concurrency model of the language runtime.
To fundamentally address this issue, we need to approach it from two perspectives:
- Client Side: How the user sends the file content to the server.
- Server Side: How the server receives the file sent by the user through specific mechanisms.
After conducting user interviews, our use case scenarios include:
- As defined by the API specifications, files will be sent using formdata, which also includes other user - information.
- The size of the files sent will vary, with a maximum size of up to 1GB.
- The client will use the HTTP/1.1 protocol to send requests.
Based on the use cases, we can now examine how the client sends requests.
Client Side: Sending an HTTP Request with Large-Size Files
從 client 端透過 HTTP/1.1 protocol 傳送檔案到 server 端,標準做法就是使用 multipart/form-data 並且將完整的檔案內容夾帶在其中送出;而此時 HTTP request 中會紀錄(using Content-Length header)整個 request body 連同檔案大小的長度資訊,讓 server 端可以根據 Content-Length header 來判斷 request 是否接收完成。
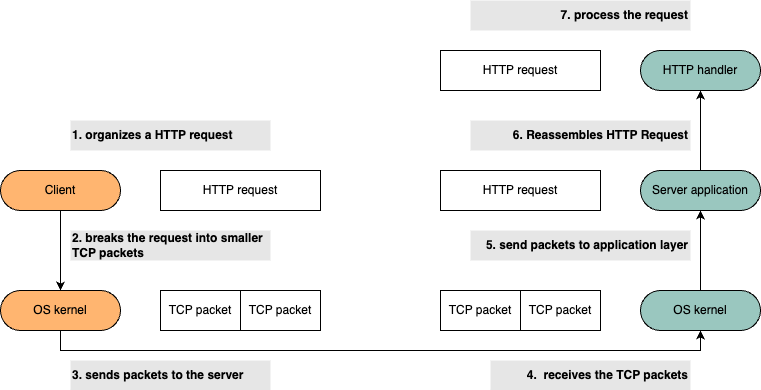
1. The client organizes a HTTP request
2. The OS kernel breaks it into smaller TCP packets and sends them to the server
3. The server OS kernel receives the TCP packets and sends them to Server application layer via the socket.
4. The server receives the TCP packets and organize them into a completed HTTP request according to the content-length
5. The server passes the HTTP request to the handlers
依據上述的 request 傳送過程,在傳送檔案長度較長的檔案時,會遇到一些潛在的問題:
- 當 request body 的長度太長時,根據 web framework 實作方式不同,有可能會 blocking 在步驟 4,因為必須等待整個 request 接收完後才會送到 handler 進行處理
- reuqest body 長度長,也意味著 server 端在重組 HTTP request 過程中會需要佔用較多的記憶體,而此時如果 user request 數量增多,將對 server 造成記憶體壓力,甚至有可能因此 server 因為記憶體不足而意外終止
傳送大型檔案而造成的記憶體不足問題,不只會發生在 server 端,同樣地也會發生在 client 端,因為 client 端也需要把整個檔案的內容讀取到記憶體中,才能組成 HTTP request 進行發送。
Streaming Data - Transfer-Encoding: chunked
如果讀取整個檔案大小的方式太佔用記憶體,那麼是否可以把檔案切分成小段再發送給 server 呢?我們可以透過 Chunked transfer encoding 這個機制來幫助我們實現此想法。
The chunked transfer coding wraps content in order to transfer it as a series of chunks, each with its own size indicator, followed by an OPTIONAL trailer section containing trailer fields.
Chunked transfer encoding 最初的想法是用來發送未知長度的 request 或 response,把資料切分成多個小段的 chunked data 並分別使用 HTTP request 送至 server,其中最大的差異就是不使用 Content-Length 來提前註明 body 的長度,而是改採用 zero-length chunk 來告知 server 此 HTTP request body 中包含最後一段的資料。
The example of chunked encoding
運用這樣的機制,原本包含完整檔案內容的一個 HTTP request,被拆分成多個包含部分內容的 HTTP request,而 HTTP handler 就可以依據需求來處理這些被分段的內容,例如暫存到本地端以供後續使用,這樣也就能避免因為資料長度過長造成的記憶體不足問題。